补充一下贫乏的基础知识
之前API嫖的爽,但是基础知识太少了。补充一点api内部知识
之前的实现用的是opencv里自带的haar分类器,
Haar分类器 = Haar-like特征 + 积分图方法 + AdaBoost +级联;
Haar分类器算法的要点如下:
① 使用Haar-like特征做检测。
② 使用积分图(Integral Image)对Haar-like特征求值进行加速。
③ 使用AdaBoost算法训练区分人脸和非人脸的强分类器。
④ 使用筛选式级联把强分类器级联到一起,提高准确率。
Haar特征分为三类:边缘特征、线性特征、中心特征和对角线特征,组合成特征模板。特征模板内有白色和黑色两种矩形,并定义该模板的特征值为白色矩形像素和减去黑色矩形像素和。Haar特征值反映了图像的灰度变化情况。例如:脸部的一些特征能由矩形特征简单的描述,如:眼睛要比脸颊颜色要深,鼻梁两侧比鼻梁颜色要深,嘴巴比周围颜色要深等。但矩形特征只对一些简单的图形结构,如边缘、线段较敏感,所以只能描述特定走向(水平、垂直、对角)的结构。
积分图:
积分图像是用来加速算法的,因此求取积分图像本身复杂度不能很高,否则就失去了意义。为了快速的计算出积分图像,需要充分利用已经计算出的结果,避免重复计算。计算公式如下:
下图是该公式的原理示意:
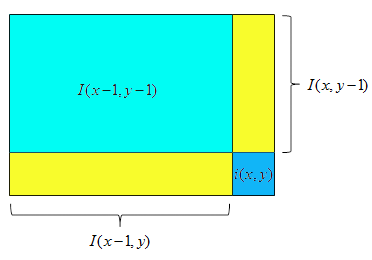
本质就是简单的迭代求和
那么求haar-like特征,就是把积分图的数角叠加,就能得到
adaboost:
太复杂了,没看懂,大概就是利用一堆haar-like的弱特征,不停的进行分类实现出一个强分类器。
级联:
本身是决策树,通过通过多次强分类器的通过,才能判定此为人脸,可以提高人脸的识别正确率
PREVIOUSSdk实现qq机器人编程
NEXT依旧没什么进展